
I’ve seen enough websites crash at the worst possible time—usually during a promo or a traffic spike—to know that ignoring server health is a mistake. If you think it won’t happen to you, let me just say: I used to think that, too.
Monitoring server performance isn’t just for large companies with dedicated IT teams. It’s a smart habit for anyone serious about keeping their online business fast, stable, and reliable. In this post, I’ll walk you through what I monitor, why it matters, and how you can stay a step ahead of potential issues—without making it your full-time job.
What You’ll Learn
- What server performance monitoring actually means (in human language)
- The specific metrics I keep tabs on daily
- How I configure alerts so I don’t wake up to chaos
- Tools I personally use and recommend
- Practical best practices that have saved me countless hours (and headaches)
What Is Server Performance Monitoring?
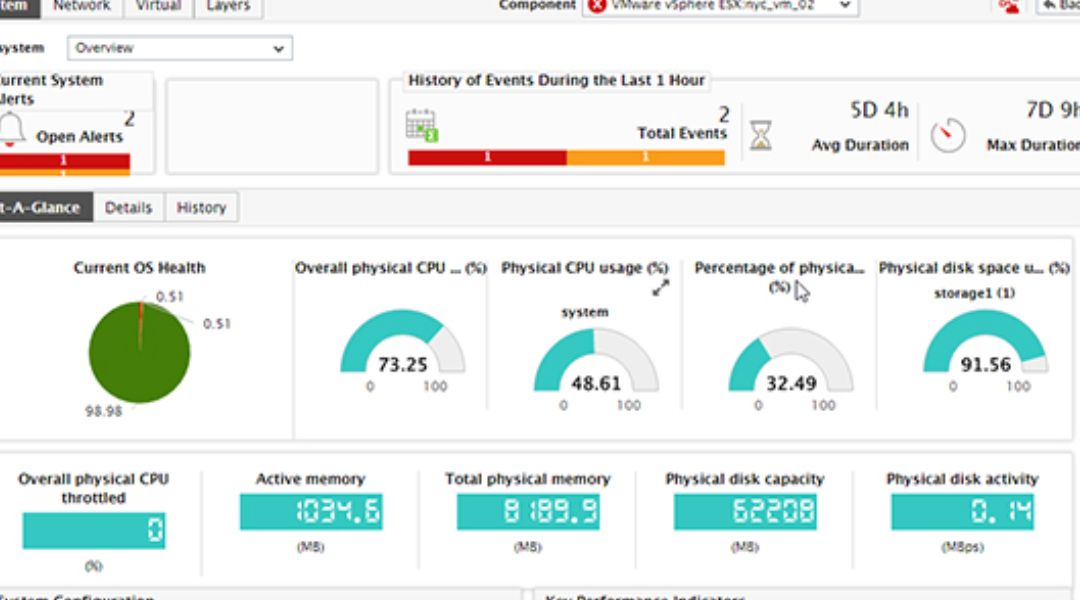
To put it simply, server performance monitoring is the ongoing process of watching your server’s key resource usage. I’m talking about CPU load, memory consumption, disk activity, and network speed.
Imagine driving your car with a broken speedometer, no gas gauge, and no warning lights. You might get somewhere, but you’re flying blind. Monitoring gives you real-time insight and lets you fix issues before they become problems.
Why I Bother Monitoring (And Why You Should Too)
I monitor my servers for four main reasons:
Better performance equals happier users.
No one likes a slow site. Users bounce fast, and those lost seconds can cost you sales, trust, and traffic.
Search engines notice.
Site speed is a known factor in search rankings. If your server can’t keep up, your SEO suffers.

Downtime isn’t just annoying—it’s expensive.
Whether you’re selling products, running a blog, or hosting an app, every minute of downtime could mean lost opportunities or angry emails.
Prevention is cheaper than panic.
When something breaks, it’s usually not the best time to figure out what went wrong. Monitoring helps me spot issues early and resolve them on my terms.
Need a structured approach to this? You’ll find some solid tips in my server management best practices article.
My Go-To Metrics: What I Actually Track
Not all metrics are worth your time. Here’s what I focus on regularly:
CPU Load
If the CPU’s under constant pressure, you’re headed for a crash. High load can slow everything down and even cause system failure.
Memory Usage (RAM)
Memory leaks can sneak up on you. Tracking RAM usage over time helps identify inefficient processes.
Disk Space & I/O
A full disk is a fast track to service disruption. Disk I/O (read/write speeds) is equally important—slow I/O can make even small tasks painfully sluggish.
Network Throughput
Your server might be fast, but if data isn’t moving quickly across the network, users still suffer.
Uptime and Downtime Logs
I aim for at least 99.9% uptime. Anything less is a signal that something’s off.
Error Logs
These are pure gold. I treat my logs like a detective treats evidence—they tell me exactly what happened and when.
Want to go deeper into optimization? My post on server optimization techniques might come in handy.
The Tools I Use (And Trust)
Not all tools are created equal. Some are bloated, others are too basic. Here’s what I stick with:
Datadog
Clean visuals, powerful analytics, and real-time alerts. It’s flexible and fits into most stacks.
New Relic
Great for full-stack visibility. Helps me see both application and server metrics in one place.
Netdata
Lightweight and ideal for quick checks. If I just want to know “Is something wrong?” it gets the job done.
If you’re new to all this, I recommend checking out my beginner’s guide to server administration for a simple starting point.
Smart Alerts: My 24/7 Watchdog
Monitoring without alerts is like installing smoke detectors and removing the batteries. I configure alerts that make sense—based on patterns, not paranoia.
For example:
- CPU usage over 85% for more than 10 minutes? I get a message.
- Disk usage past 90%? Time to clean up or expand.
- Sudden spikes in error logs? I know something’s off.
The trick is to set thresholds based on your server’s normal behavior. Otherwise, you’ll get alert fatigue and start ignoring them—defeating the purpose.
Reports That Actually Matter
Every week, I review performance reports. This includes:
- Load trends over the past 7 days
- Memory usage changes
- Disk and network activity
- Any patterns in log entries
You don’t need fancy visuals. Just consistency and attention. Reports are how I spot slowdowns before they become support tickets.
If you’re working with Apache or Nginx, this checklist might help tighten things up.
Best Practices From Years in the Trenches
Here’s what I’ve learned through trial, error, and a few server meltdowns:
Tune your server often.
Web servers, databases, and caching layers all benefit from periodic review and adjustment.
Automate where possible.
From log rotation to backups, I let scripts handle what doesn’t need my full attention. Here’s how I automate my server maintenance.
Quarterly audits are worth it.
I take time every few months to review performance baselines, log trends, and security patches.
Backups are non-negotiable.
It’s not a matter of “if” something goes wrong, it’s “when.” I keep multiple versions, stored offsite.
Real-World Example: Catching a Memory Spike
I once worked with a client whose site slowed down drastically after every new blog post. Monitoring showed a memory spike every time traffic surged. Turned out, a third-party plugin was caching way too aggressively—and not releasing memory.
We swapped the plugin, tweaked some server configs, and suddenly the site loaded 2.3 seconds faster. Their bounce rate dropped 18%, and average time on site went up. All because we caught a problem before it turned into a disaster.
Final Thoughts
You don’t have to monitor every single byte. But if you’re serious about performance, reliability, and scalability, you need some kind of monitoring in place.
Set up alerts. Watch your key metrics. Review reports. Fix small problems before they grow legs and start running wild.
And if you’re still relying on luck? Well, I hope your backups are recent.
{kind=link}